하위에서 상위로 누적 합계 구하기
아래는 현재행을 시작점으로 하위에서 상위로 누적합계를 구하는 예제이다.
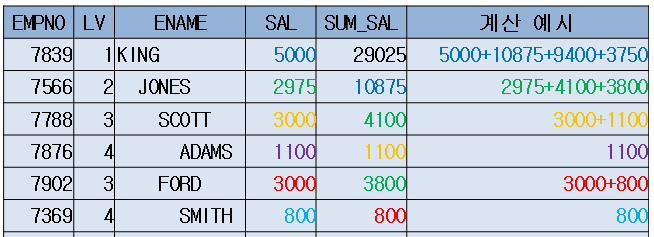
SELECT empno
, LEVEL lv
, LPAD(' ', (LEVEL-1)*2, ' ') || ename AS ename
, sal
, (SELECT SUM(sal)
FROM emp
START WITH empno = a.empno
CONNECT BY PRIOR empno = mgr
) sum_sal
FROM emp a
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr
;
EMPNO LV ENAME SAL SUM_SAL
------- ---------- -------------------- ---------- ----------
7839 1 KING 5000 29025
7566 2 JONES 2975 10875
7788 3 SCOTT 3000 4100
7876 4 ADAMS 1100 1100
7902 3 FORD 3000 3800
7369 4 SMITH 800 800
7698 2 BLAKE 2850 9400
7499 3 ALLEN 1600 1600
7521 3 WARD 1250 1250
7654 3 MARTIN 1250 1250
7844 3 TURNER 1500 1500
7900 3 JAMES 950 950
7782 2 CLARK 2450 3750
7934 3 MILLER 1300 1300
현재행을 시작점으로 스칼라서브쿼리에서 계층구조를 전개하여 합산을 한다.
CONNECT BY LEVEL을 이용한 테스트 샘플데이터 생성
프로젝트 진행시 테스트 데이터 생성이 필요한 경우가 있는데 CONNECT BY LEVEL을 활용하면 손쉽게 테스트 샘플 데이터를 생성 할 수 있다.
아래 예제와 같이 CONNECT BY LEVEL을 사용하면, 특정 LEVEL이 될 때 까지 ROW를 출력하는 것을 알 수 있다.
-- 10개의 ROW를 출력하는 예제이다.
SELECT LEVEL FROM DUAL CONNECT BY LEVEL <= 10;
-- 10개의 ROW가 출력된다.
LEVEL
-------
1
2
3
4
...
10
위 CONNECT BY LEVEL의 원리를 이용하여 아래와 같이 테스트 샘플데이터를 만들어 보자
-- 10 만건의 데이터를 가지는 emp_sample 테이블을 생성하는 예제이다.
CREATE TABLE emp_sample AS
SELECT -- 1. EMPNO(Unique 컬럼)
LEVEL empno,
-- 2. JOB(천만건 데이터를 10개 그룹으로 분류)
'SALESMAN_'||CHR(65 + MOD(LEVEL , 10)) job,
-- 3. HIREDATE(금일+9일까지)
SYSDATE + MOD(LEVEL , 10) hiredate,
-- 4. DEPTNO (0, 10, 20, 30, 40)
MOD(LEVEL ,5)*10 deptno
FROM DUAL
CONNECT BY LEVEL <= 100000;
-- 테이블과 데이터가 정상적으로 생성되었는지 확인해 보자
SELECT * FROM emp_sample WHERE ROWNUM < 10;
EMPNO JOB HIREDATE DEPTNO
----- ----------- -------- ----------
1 SALESMAN_B 11/06/28 10
2 SALESMAN_C 11/06/29 20
3 SALESMAN_D 11/06/30 30
4 SALESMAN_E 11/07/01 40
...
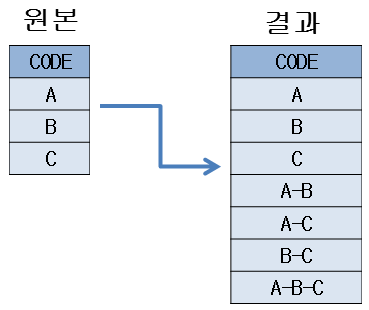
경우의 수 조회
이번 예제는 그림과 같이 (A, B, C) 3개 코드 조합으로 나올 수 있는 모든 경우의 수를 조회하는 예제이다.
- [그림] 경우의 수
아래는 계층구조쿼리를 사용하지 않고, UNION ALL을 이용하여 작성하였다. 아래 쿼리는 self 조인과 UNION ALL 조합의 한계가 있다. 코드의 개수가 늘어날 경우 SQL 수정이 불가피 하다.
WITH test AS
(
SELECT 'A' code FROM dual
UNION ALL SELECT 'B' FROM dual
UNION ALL SELECT 'C' FROM dual
)
SELECT a.code
FROM test a
UNION ALL
SELECT a.code ||'-'|| b.code AS code
FROM test a
, test b
WHERE a.code < b.code
UNION ALL
SELECT a.code ||'-'|| b.code ||'-'|| c.code AS code
FROM test a
, test b
, test c
WHERE a.code < b.code
AND b.code < c.code
;
CODE
---------------
A
B
C
A-B
A-C
B-C
A-B-C
7 rows selected.
코드의 개수가 늘어날 경우 SQL 수정이 불가피하다.
아래는 계층구조쿼리를 사용하여 경우의 수를 조회한 예제이다.
WITH test AS ( SELECT 'A' code FROM dual UNION ALL SELECT 'B' FROM dual UNION ALL SELECT 'C' FROM dual ) SELECT SUBSTR(SYS_CONNECT_BY_PATH(code, '-'), 2) code FROM test CONNECT BY PRIOR code < code ORDER BY LEVEL, code ; CODE ----------------- A B C A-B A-C B-C A-B-C 7 rows selected.
부등호 조건(PRIOR CODE < CODE)을 이용한 계층 전개 계층전개 조건이 반드시 이퀄(=)조건일 필요는 없다.
순서까지 고려한 모든 경우의 수
이번 예제는 순서까지 고려한 모든 경우의 수이다.
- [그림] 모든경우의 수

WITH test AS ( SELECT 'A' code FROM dual UNION ALL SELECT 'B' FROM dual UNION ALL SELECT 'C' FROM dual ) SELECT SUBSTR(SYS_CONNECT_BY_PATH(code, '-'), 2) code FROM test CONNECT BY NOCYCLE PRIOR code != code ORDER BY LEVEL, code ; CODE ------------------- A B C A-B A-C B-A B-C C-A C-B A-B-C A-C-B B-A-C B-C-A C-A-B C-B-A 15 rows selected.
- – 부등호(!=) 사용시 순환구조 발생 (예: A-B-C-A-…)
- – NOCYCLE 사용으로 에러 방지 (예: A-B-C (여기까지만) -A-…)